

There are great books out there written on how to write clean code(my favourite is indeed Code Complete). They will explain how it's important to split responsibilities, use the same level of abstraction among functions in the file and 129 other rules.

Clean code indeed is infinitely better from the maintainability perspective. It is testable, understandable and nice. But is there a case where it makes sense to write some shitty code? Let's figure out.
Business Context
So, at supplied, we need to verify that business we check actually exists and have the correct information about the company address, business name, vat address, owner name and other details.
We support several countries in Europe right now. It means that we need to call different APIs, which provide responses in different formats having different set of data. Some APIs will return you the owner name, some will omit it; some will give you the full address; some don't. Etc.
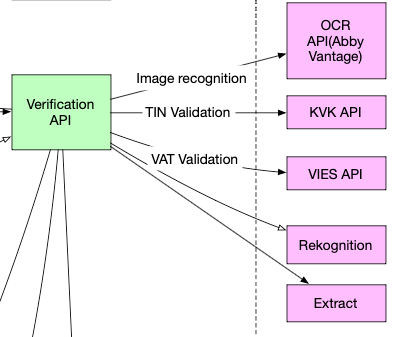
Initial Solution
But it's important to know the business situation. We started with verifying just Netherlands businesses, so the solution was to hack the solution shortly.
async runNLBusinessChecks(verification: Verification) {
const nlBusinessReg = this.findDocument(verification, DocumentType.NLBusinessRegistrationId);
if (nlBusinessReg) {
const { parsingResult } = nlBusinessReg;
console.log('Checking NL Business: parsing result', parsingResult);
if (parsingResult && parsingResult.Values) {
const kvk = parsingResult.Values["registrationNumber"];
const address = parsingResult.Values["address"];
const legalName = parsingResult.Values["legalName"];
const ownerName = parsingResult["ownerName"];
// perform the checks
}Eventually we added Belgium and Germany, as well as the VAT number check. So the method would grow significantly:
async runNLBusinessChecks(verification: Verification) {
const beBusinessReg = this.findDocument(verification, DocumentType.BEBusinessRegistrationId);
const nlBusinessReg = this.findDocument(verification, DocumentType.NLBusinessRegistrationId);
const euInvoice = this.findDocument(verification, DocumentType.EUInvoice);
console.log('Checking NL Business: nl business reg', nlBusinessReg);
if (euInvoice) {
// checks for vat
}
if (nlBusinessReg) {
//checks for NL
}
if (beBusinessReg) {
// checks for BE
}
// check the results
}This looks dirty at least. Here's a short list of problems with this code:
- Very difficult to test
- No scalability. Adding a new country is a new if
- Long error-prone method
Solution
At this point the high-level idea of the solution is pretty clear. We need to introduce an abstraction like a Verificator interface. It will incapsulate the following logic:
- Taking the data from the related document and put it into the appropriate place in the verification object
- Call the external api
- Make the relevant checks
Then we can create a Verificator per country which would handle the document of the appropriate type and change the general logic to work with the Verificator instead of writing ifs:
async runBusinessChecks(verification: Verification) {
const country = verification.contactInformation.businessCountryCode
const verificator = this.verificatorFactory.createVerificatorForCountry(country as CountryCode)
await verificator.fillExtractedData(verification)
const matchResult: CountryBusinessVerificationData = await verificator.checkMatch(verification) as CountryBusinessVerificationData;
// check the results
}It looks so much better! We can now also cover each verificator with a unit test and be happy about it.
A case for shitty code
Now you can say, so, why the hell you didn't go for this abstraction in the first place. It was so obvious you gonna expand to more countries!
Well, it wasn't. The nature of startups is that you don't know what happens tomorrow. You can get a huge client and several hundred thousand contract, or you can go bankrupt. So putting a lot of efforts into abstractions can be critical for the survival.
Another argument is that now, supporting at least 3 countries and vat checks we can tell how the appropriate abstraction looks like. It was nearly impossible to come up with at the stage with a single country. Wrong abstraction would slow us down and cause huge pain later - even bigger than refactoring a bunch of intentionally shitty code. So I am actually glad we used this approach.
TL;DR
As usual in software development, shitty code vs clean code is not an obvious choice, but rather a tradeoff. You should know what to pick depending on the business context including your current goal. Take only calculated risks!
Liked the article? Subscribe to the Architecture Weekly newsletter right here. Or if you want to learn how to design complex systems to solve business problems, you can join the course!