

One of the responsibilities of an architect is to ensure that the system fulfills its requirements. There is plenty of experience and information on how to setup quality control for functional requirements. In short, you combine multiple practices to ensure quality. The team performs code reviews, develop unit-tests, setup static analyzers, develop and run manual tests, develop automated end-2-end tests etc. The problem here is it is usually done only partially, and it's usually missing testing of non-functional requirements, also known as architecture attributes. In this article I will compare functional testing to testing of architecture attributes, provide the tactics for testing performance, security, availability and maintainability and describe an approach of continuous testing.
Unfortunate aspects of NFRs
Different kind of requirements
Testing functionality is relatively straightforward(oversimplified intentionally): take the view of your users, write down the scenarios, go through them, think about combinations of features, observe the result and compare it with the expected. Say, we are testing the login screen of a mobile application.
You need to enter some valid pairs of login and password and press login, ensure they work. Then enter some invalid password, ensure there is a proper error message. Then try to enter some invalid email and check the validation. At last, you try to disable internet connection and observe the proper error. Pretty much it.
This approach does not work with something like performance: a single performance measure of a particular use case does not tell anything about the ability of the system to perform accordingly to the requirement. If it performs well, you just might be lucky. If it performs poorly, it might be a problem with a particular user, network lag or something else. So, you need a completely different approach. Usually, such requirements include a measure and some statistical value, where this measure should be observed. For example: "The response time for a static webpage should not exceed 500 ms in 99 percentile". That means that in 99 cases out of 100, the page should be loaded in half a second, and in one case it may exceed that value. More on percentiles here. Same thing works for availability: we typically want the system to be available 99,9% of time or something like that(we call it 3 nines).
Cross-cutting concerns
Another problem with NFRs is that they are cross-cutting: the team may accidentally break them unintentionally while developing a new feature.
Imagine you're a developer and you make a new feature, say adding stories on the main page of your application. Everything works well from your point of view and you ship the feature to production. However it appears that with stories the main page now loads half a second later and it starts to affect the business metrics and people launch the app less frequently and you start to lose money. If you had a proper performance test for that you could prevent such situation.
Is it that bad
The fortunate thing about testing NFRs is that actually overall approach is not that different from functional requirements or constraints. You still may use static analysis for some part of security testing; you can write end-to-end testing focusing on performance; there exist unit test even for maintainability and architecture like ArchUnit. In the end, the difference is within internal methods and tools, but not the overall approach itself. I will get back to the approach later in this article. Now I want to focus on the testing of particular NFRs.
Testing NFRs
Performance
As per Neil Ford's "Fundamentals of Software Architecture", you may see the system from the perspective of architecture quantas: groups of components with same non-functional requirements. Let's say you make an url-shortener: you accept a small portion of user data for a big amount of users; at the same time you need a small web interface to see the analytics on the link usages. The first part is heavily loaded and should be highly available; the second part though will have 1 or 2 users and should be available like business hours.

Those 2 parts have different performance requirements and require different testing. Moreover, the consequences of performance degradation is different as well. So the idea is that you need to come up with performance testing not for the whole systems but for quantas.
When talking performance we need to distinguish the reads and writes, and properly collected requirements usually do that. We can require the webpage to load under 1 second 99.9% of time. We can also want that form submission yields result in under 5 seconds 99% of time. Those are different requirements and should be tested individually, meaning testing the former gives zero information on testing the latter.
The next issue with testing performance is using the right load. Returning to webpage load under 1 second. But in what circumstances? It might be very easy to do under 1 concurrent user, and much harder under 1000 ones. Also, the problem is you can not test form submission with some random data. You will have to at least test against minimal input, average input and some extreme values. Long story short, you need to know your load model and run your tests against it. Otherwise you know little about your system from load perspective.
Testing environment is usually a problem as well. A lot of parameters of your system affects the performance yield. Replica count affects the number of concurrent users; resource allocation(cpus and memory) limits the max load; storage limits the size of your databases, etc. And here you face the dilemma: either you test in production, or spend a budget on having a separate environment and setting up complex procedures to replicate anonymized production data in a perf env. There is no proper general answer, and you need to weight for your system.
As an example of production performance testing for a highly popular service, please refer to the article by Netflix. Netflix cares a lot about user experience and performance is its crucial aspect. With large user base of 200+ millions viewers and the wide variety of the devices proper performance testing should be in place. The article discloses approaches and measures to ensure no performance regressions reach production.
Security

Security does not make the life of an architect easier in any way you can imagine. You still can not test a feature and say the system is secure and similar to performance you need a model. This time it is a risks & threats model. For example, a simple version of url shortener without user accounts requires data durability and some form of DoS protection; a bank requires a paranoidal level of security on the other hand.
With security testing you need to ensure you don't disclose the data, you keep it unmodified and make it available.
As with all the other attributes, there is no single measure which will guarantee the security; instead you use different tactics. Security should be addressed on each stages of product development: analyze security requirements during design phase, design secure architecture (plan security controls to mitigate relevant risks), follow secure coding guidelines according to your app’s stack, validate app’s behavior. This cycle is also known as SSDLC (secure software development lifecycle).
Vulnerability static analysis is a code scanner similar to the code checks, but instead of correctness it searches for the security issues. As examples you can check for hardcoded credentials, logging PII and PHI, sql injections, etc. The top vulnerabilities are tracked by OWASP foundation and security scanners should check at least for TOP 10. Frequently, such kind of tools also check your dependency graph for know vulnerabilities as well, but if not, there are standalone tools. Also, it may be a part of a package manager(like NPM) or your code storage solution(like dependa-bot in Github).
Static analysis only works via reading the source code; Dynamic Application Security Testing(DAST) tries to run your code and break it from the security perspective. Automation tests try to exploit different types of vulnerabilities in dynamics in contrary to static analysis. For example, instead of search for a potential sql injection in code, DAST will try to insert sql queries in your API or user input and see if it breaks the app. DAST does not replace, but rather complements static analysis.
Other tactics is Penetration Testing. Briefly, Pen Test is like trying to ensure your house is robber-proof by trying it to rob it yourself. From the software system perspective it means that a group of people with proper skillset try to breakthrough into the system and achieve the highest privilege. After all the attempts they create a report with all the methods and tools used, the achieved results and a list of recommendations. The responsible people should evaluate this report carefully, prioritize the issues and take actions to remediate them. A retest is advised after the issues are fixed. This activity is recommended after changing network configurations, adding new segments, updating the software and in general after every change. Also Pentests should be run once in a while: every 6-12 months or after a large changes in your product. Don’t forget that penetrations tests only try to find vulnerabilities from outside, while secure development practices ensure your developers cover security weaknesses from inside before they become exploitable vulnerabilities.
Maintainability

By maintainability we understand our ability to change and grow our system according to evolving requirements. If the system is designed poorly, the price of changing it grows lineary or even exponentially with time rendering it impossible to extend. However, not only the initial design matters, but how we evolve it as well. Bad decisions, writing the low quality code, omitting unit tests leads to decreased time to market. Despite perceiving as something binary(is it easily changeable or not), we can actually measure maintainability.
First you would like to monitor relevant code metrics. Although cyclomatic complexity, cohesion, coupling, unit test coverage, todo's count do not tell much by themselves, you can measure overall picture to say if you're moving in a right direction or something is going wrong. Typically static code analyzers are able to gather all of those metrics. Unit test coverage can be an exception, but there is a tool for virtual every programming language out there.
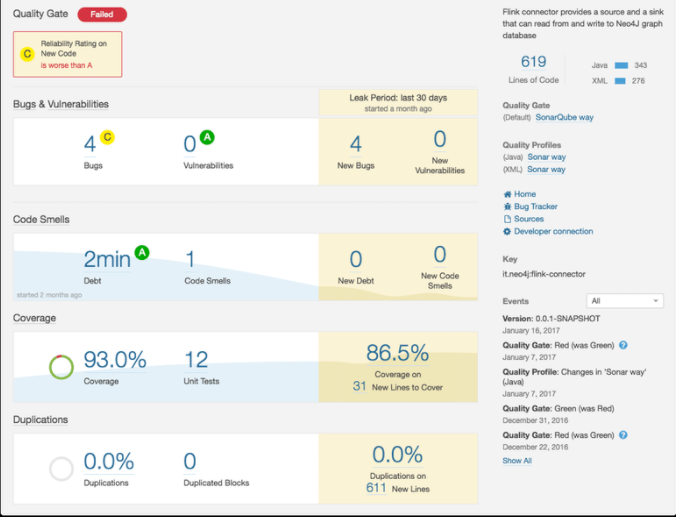
From the architecture perspective you can assure your applications are structured according to the rules. For example you can enforce hexagonal architecture in a Java application by using ArchUnit. It also works for .NET as well. All you need is to write the unit tests and run them as usual.
Another aspect of maintainability is the system architecture.
Availability

Every software system has their availability requirements. For example the accounting system for a single time zone may require to be available only during working hours like Monday through Friday 9.00 AM - 6.00 PM. Other systems like social networks should be available most of the time. The question is can we require 100% availability? Well, we can, however every nine in this attribute comes with an exponential price. For example, availability of this blog is like 99%(we say '2 nines'), and it's perfectly fine. Adding a single 9 and making it 99,9% will come with a 100% cost increase, as it may require an additional VM and some load balancing. Making it 99,99% will double the price as well, as a new region would be required. So every enterprise should understand what availability will be required and sufficient from the business perspective.
There are different types of availability, like point or mean, or steady state etc, however the difference between them is subtle and basically just formula-wise.
For such an attribute we need special tactics to ensure we hit our availability target. In order to do so we employ both theoretical and empirical approach.
Speaking theory, you need to calculate the maximum possible mean availability of your designed system. In order to do so, you need to know SLAs of your components, and apply the probability multiplication formula. More on the calculations here.
The empirical approach is to collect the statistics on how much time the system was actually available from the end user perspective. In order to implement it you need some system which will reach a special endpoint in every service making your system and receive a liveness status. There will be some failed requests; having the successful/failed requests ratio will give you the availability checkmark. Then you can make dashboards and alerts to know if you really support your target availability there.
Continuous Testing
We discussed several non-functional requirements testing and discovered the corresponding approaches and tools. However, you can't just apply a tool once and be happy; you need to continually know the NFRs are fulfilled and fix the system otherwise. That approach applies both to NRF testing and functional testing. However, in order to apply it you need a holistic complex approach.
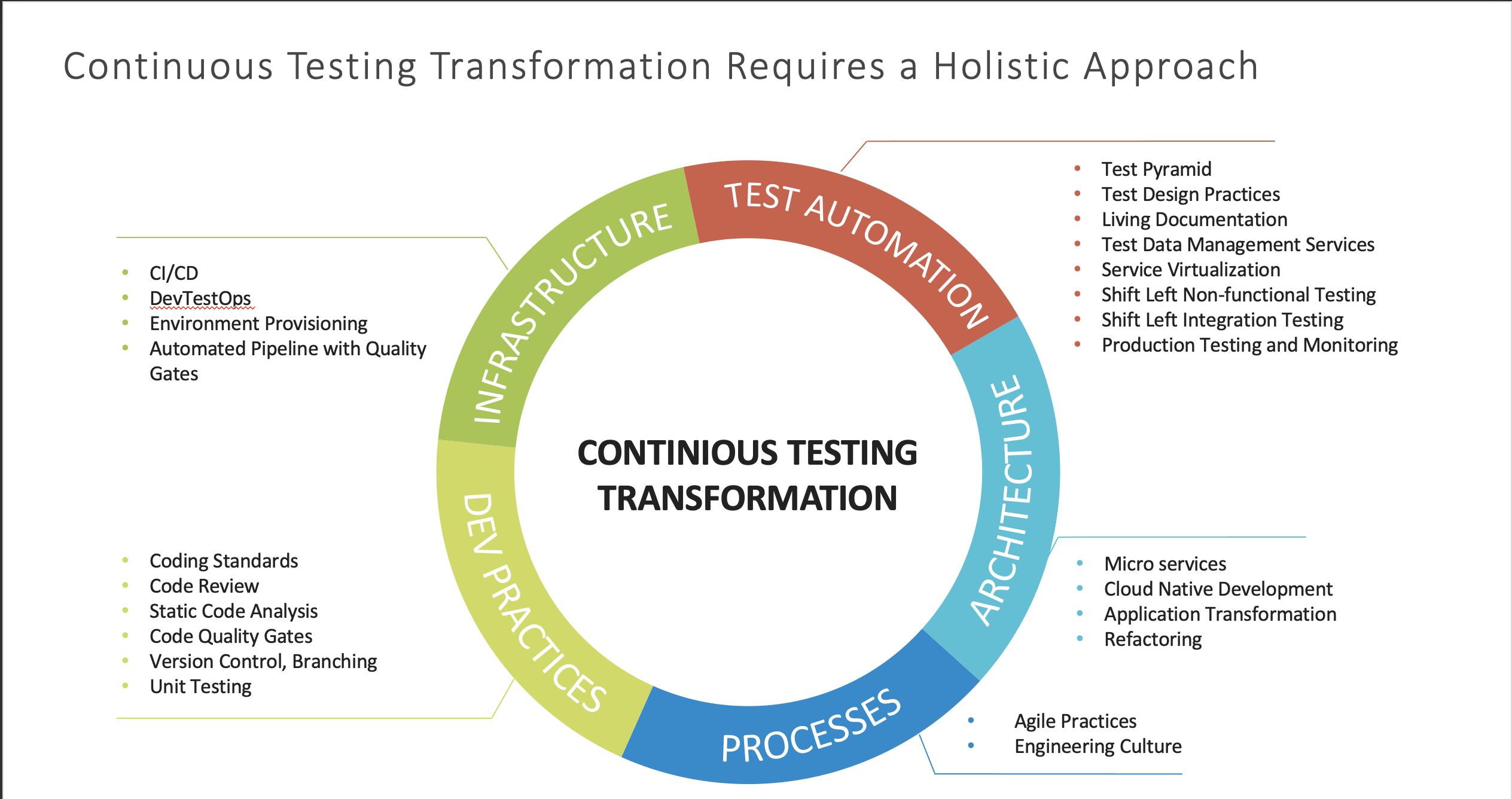
Development practices
First of all we need to apply quality gates to every step of our value stream. We will run classic static code analysis, security scan, unit tests run and coverage test. We will also run DAST and performance tests on the binaries in dedicated environments.
Infrastructure
The practices above require a lot of churn to be automated: building artifacts from source code, provisioning environments, running tests, forbidding merge requests, sending emails etc.
Test Automation
As we spoke above, both functional and non-functional requirements require constant feedback from tests. You can not afford not having those tests automated due to straight labor cost and increased time to market. You also need to shift those test runs as far left as possible.
Architecture
Obviously, architecture that does not support your requirements will fail the project. That means that application design is not done once: it should evolve during the project and should be assessed with every new feature you incorporate. Unfortunately, we don't have tools to automatically do that for the whole systems; however the ADRs, RFCs and architecture oversee should help.
Processes
Your processes should support agility and all other aspects we spoke here. React to your team input and adjust them for the product value.
Continuous Testing Blueprint
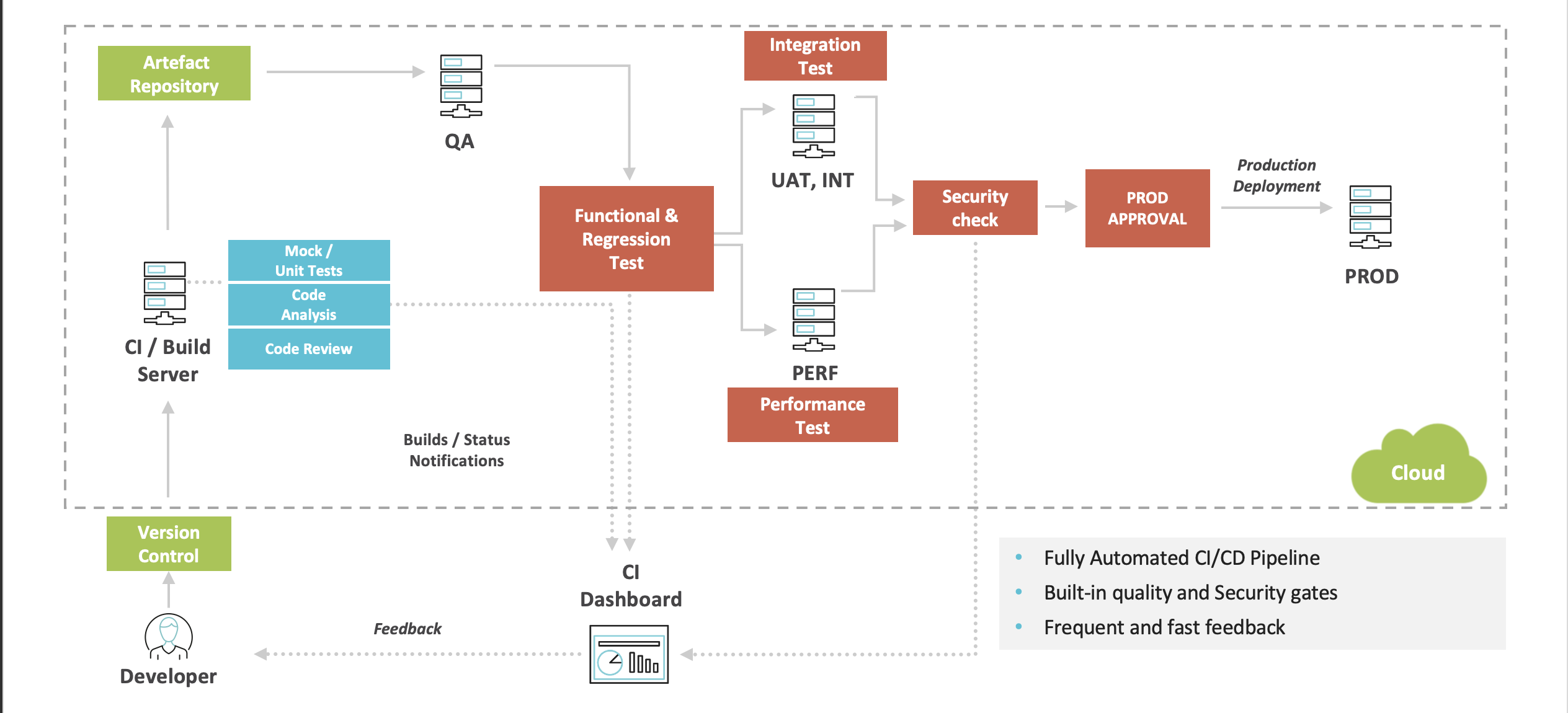
Here you can see how the value stream can look like with the approach incorporated. Once the developer commits the code or creates a merge request we build the application and run the analysis and unit tests. If the checks are succesful we place the artifact into a repository and deploy to QA environment where we can run functional tests; we also deploy the app to performance, integration and security testing environments to test other NFRS; once those checks are done, we can be pretty sure we can successfully deploy to production.
There are several important things in this blueprint. First we want to minimize the feedback time. If something is wrong we want to notify the developer as soon as we know. That's why the CI should send an email once the problem the identified, and test reports should be generated once the test suites are done.
Another thing is a dashboard where we can see the test results, highlighting the issues with performance, availability or discovered vulnerabilities.
This way we can ensure the product quality is high and adhere to our requirements.