

Let me guess: your Android app downloads some data from the network. Gotcha, huh? Let me guess more: part of that data would be eventually cached in the app. 2 of 2? But it doesn’t have anything to do with my superpowers, just the majority of the mobile apps are like this nowadays. We’re caching user profiles, app settings, images, emails, location related data and many more.
In the past, we tried to solve those problems with AsyncTasks, Loaders, and RxJava. Let’s check how we can do the same with Kotlin Coroutines. But first, let’s talk about caching in general.
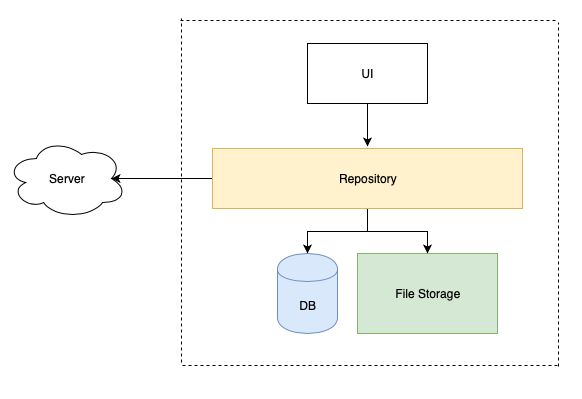
The principal scheme of our app is on the diagram above: some UI layer requests the Repository layer which is responsible for returning the data. The repository can either send a request to a server or obtain the data from the local sources like a database or file storage; it doesn’t really matter at the moment. What’s really important is the algorithm we use to store, retrieve and update the data. So let’s take a look at the caching strategies available.
Lazy cache
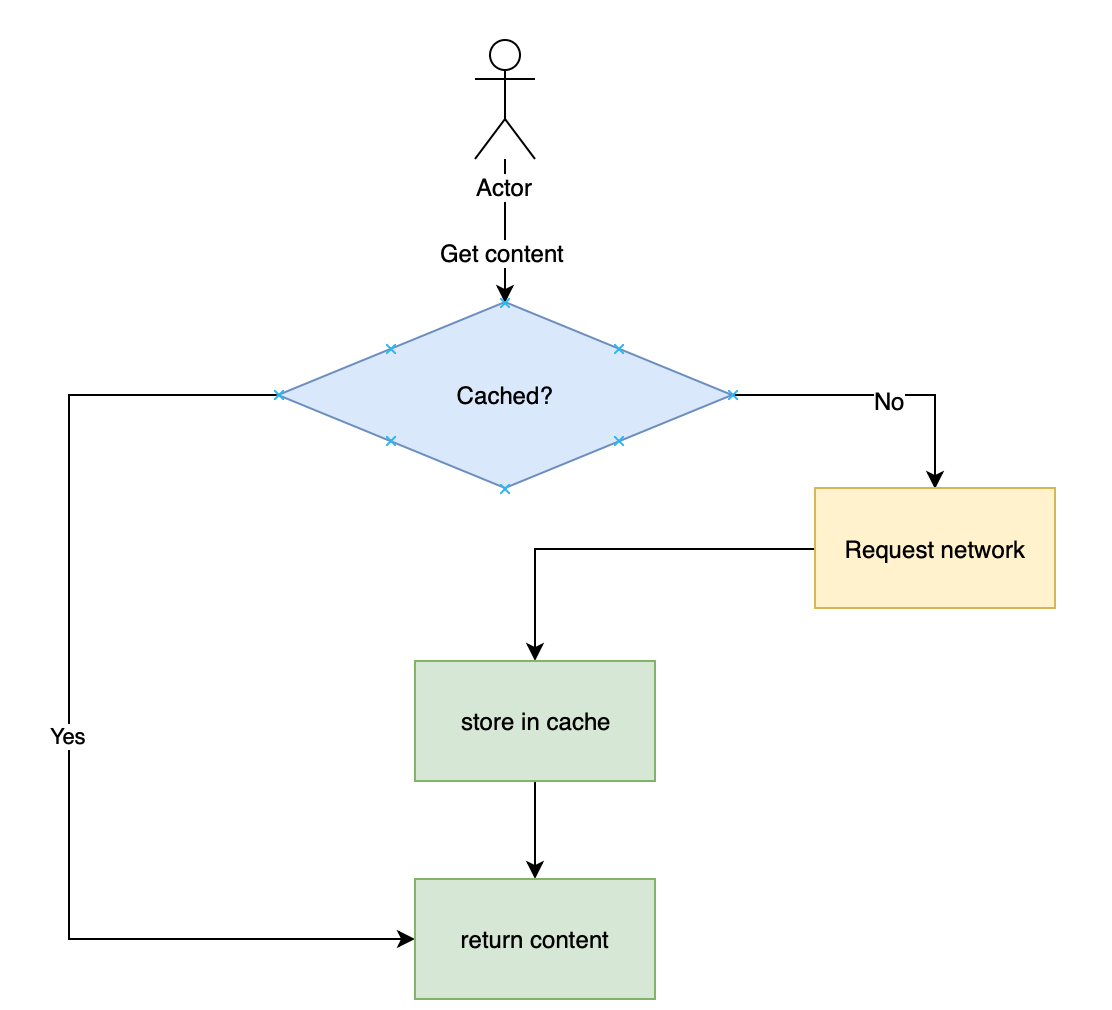
So, once we need to get the content we check if we have a cached version of it if so, return it to the UI, else — request from a server, save the content to cache and show it.
Imagine you have a two-level cache with in-memory and persistence storages. Then a particular request may be implemented the following way with coroutines:
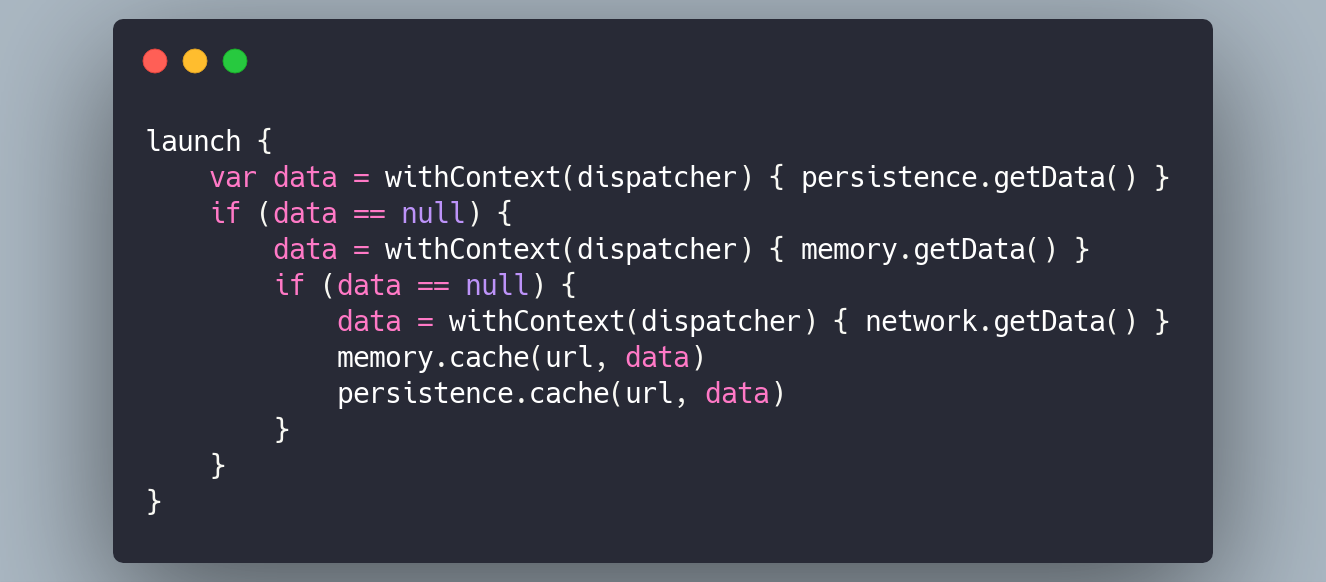
But what if I want to check the server if there is an update for my content before showing it? For example, if we have a document of several megabytes cached we better ask if the document has changed before redownloading it.
This is going to be another strategy which is called Synchronized Cache.
Synchronized Cache
The algorithm is the following:

Moreover, if you start actually implementing a cache in production many more questions arise:
- Would you do that for each data request in your app?
- How do you handle errors?
- What if you want that cache to be expired in N minutes?
- What if you want to limit the storage by M megabytes?
I believe this would be rather difficult to implement it by yourself. You definitely want this burden to be dealt with for you. You definitely want just to have a way to declare how it should work instead of actually implementing that.
What if there is already a way to do it? For example, you want to cache some data only for 1 minute and then request an update for the data, but if the update fails still use the data from cache? It’s already solved for us! Welcome, CoroutineCache library! It is storing the data in file storage as well as in memory, controls the cache size and lifetime of the stored items.
After we add the library to our project…implementation 'com.epam.coroutinecache:coroutinecache:0.9.0'
we will define the interface of our cache:

Now we need to configure the cache instance we are willing to use:
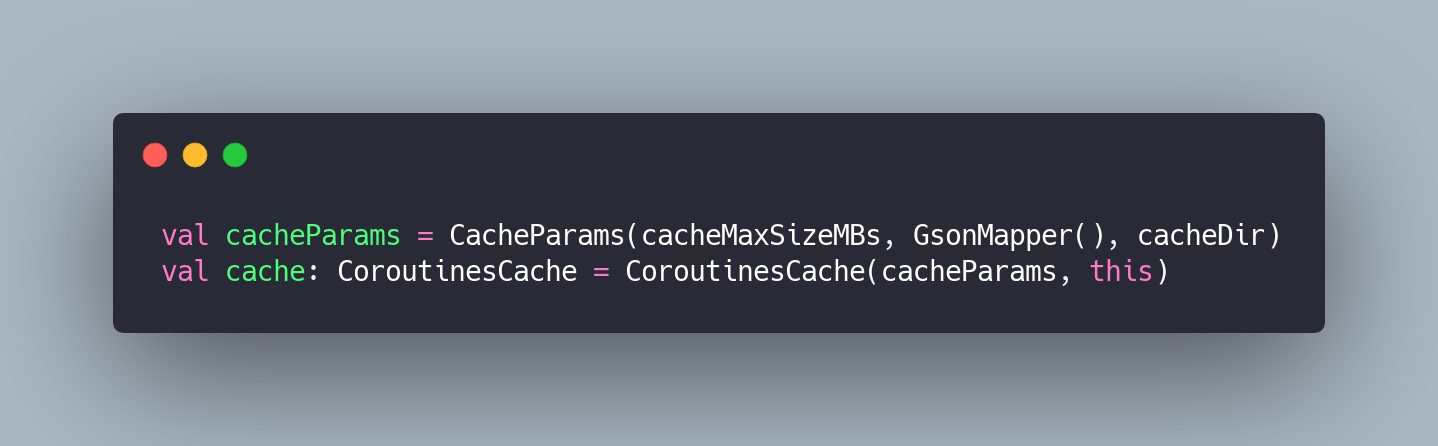
The first argument is the size in megabytes we don’t want the cache to exceed.
The second argument is the mapper to marshall/unmarshall the JSON documents which will be cached. We go with GsonMapper() here but you can pick JacksonMapper() or build a custom one.
The 3rd parameter of the CacheParams constructor is the root directory which will be used for caching. For Android, you can pick your Cache directory because it is its primary purpose.
Also, pay attention to the second argument of CoroutinesCache constructor — we’re passing an instance of CoroutineScope there, which otherwise will default to GlobalScope.
The last step is to configure what network call will be used to actually get the data we are going to cache. As Retrofit is the most popular library for API clients, I believe you already leverage it in your app with its Coroutine Adapter.
So our Repository class(remember the first diagram?) may look like this:

Here the getData() method will return you a Deferred, which you can use in your coroutines:

Great! You added caching to your network call.
How it works
You may already guess that during CoroutinesCache.using() call the library is creating a Proxy to CacheProviders interface. During the call of the methods of that proxy, the library will check the annotations and will ask the cache for the value. If it is expired the new data will be requested, and that new data will be cached, checking if the storage is not exceeded. That implementation allows for a declarative way to have caching thus allowing you to make offline first apps much easier than before.
Instead of conclusion
The library is in the phase when the first implementation is done; however, we are not sure where to go further. For example the full Synchronized cache flow or LRU cache are not implemented yet. Once you found the library interesting for your project, I am kindly asking you to give us feedback in the form of issues or even pull requests!
P.S. Many thanks to Danny Preussler, Yonatan Levin and Kirill Rozov for help with making this article better.
P.S.2 If you liked this article don’t forget to subscribe. Also, come to say Hi on twitter!