
Architecture Weekly Issue #32. Articles, books, and playlists on architecture and related topics. Every record has the complexity indication: 🤟 means hardcore, 👷♂️ is technically applicable right away, 🍼 - introduction to the topic or an overview. Now in telegram as well.
WARNING 🇺🇦
It's already been 186 days since the crazy, brutal, unjustified war of Russia against Ukraine. We condemn this war and want it to stop ASAP. We continue this newsletter so you can advance your skill and help the millions of Ukrainian people in any way possible.
Domain-Driven Design Aggregate Store 👷♂️
ORM are an anti-pattern. If so, how do we store DDD's aggregates? One way to do that is to place them in a document in an appropriate DB. But if you track the events of changing the aggregate, you need a transaction for it. MongoDB nowadays supports cross-collection transactions. Vaugh Vernon describes a way to do the same in PostgreSQL.
 Vaughn Vernon
Vaughn Vernon
Big Deal about key-value databases 🍼
Modern databases are extensible in the sense that the DB engine can be swapped. And surprisingly the relational databases can work using a key-value engine. The article explains why it can be useful and how it works in the first place. Can be useful to build your own DB!
Circuit Breakers for Slack's CI/CD 👷♂️
Circuit Breaker is the most famous backend pattern used to stop issuing the request to a failed service. The same problem hits the CI/CD systems with scaling teams and the number of features. Read how the pattern helped scale CI/CD pipeline for Slack development.
 Frank Chen Sr. Staff Software Engineer
Frank Chen Sr. Staff Software Engineer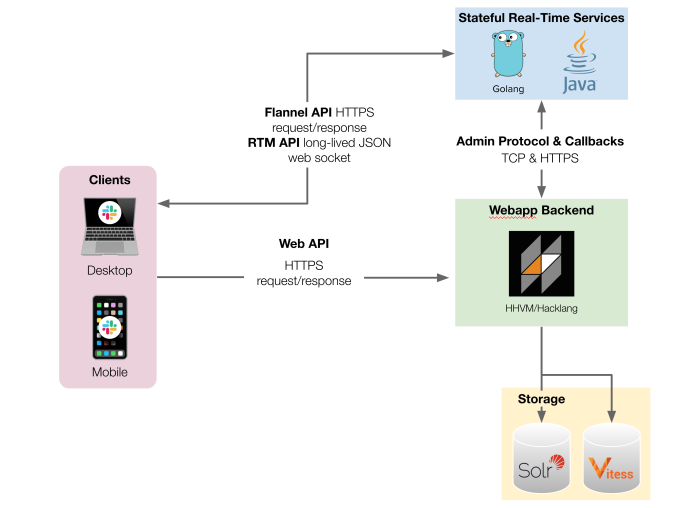
Data Streaming for Microservices using Debezium 🍼
Capturing Data Changes might be required to replicate data, write data to DWHs or to put it to secondary storage like ElasticSearch. However, doing it reliably and performant can be challenging. See a video of how the CDC problem can be solved with the Kafka-based Debezium system.
Rough Notes about CQRS and ES 🍼
Following some discussion in private architects chat, I decided to find some info on event sourcing approaches combined with the CQRS pattern and found the repository which contains some notes from articles and talks on the topic. Best practices and recipes included.
 262588213843476
262588213843476
Kubernetes Crash Course for Absolute Beginners 🍼
If you spent the last several years talking to stakeholders and drawing diagrams(like me), you might have missed the practical experience we frequently use to orchestrate containers - Kubernetes. In such case try to get through with a crash course which guides you through basic K8s components and service deployment.
Evolving Clock Sync for Distributed Databases 🤟
Clock synchronisation is a crucial mechanism to ensure the guarantees a distributed database can provide. Read how the approaches for time sync evolved with time in an article by Karthik Ranganathan.

Devs don't want to do ops 🍼
DevOps is a paradigm to break the conflict between developers wanting to roll out features and system administrators who wants a stable system. However, pushing the operational responsibilities to devs increased the demand in skills and in work done. An article describes the problem and ask the question if the platform teams are a solution.

Delivering billions of messages exactly once 👷♂️
A 5-year-old article from Twilio where Amir Abu Shareb shares how they improved their message delivering system(which is a core of the business) to be as close to deliver-only-once through sophisticated deduplication using Kafka and RocksDB.

Improving the Experience of Making Envoy Route Changes 👷♂️
A short article on how Lyft improved their developer experience while changing Envoy routes to microservices. They introduced their own solution using the configuration in JSON stored in S3. More details inside.

This newsletter is hosted on GCP and uses Mailgun to send emails. The cost is ~$25 per month. Liked it? Consider helping to run this newsletter at Patreon :)