

Task
- Collaborative Edit of a text document
- The document can have basic styling, include links, images and comments
- The access should be authenticated
- Users can be readers, commentators, editors and owners
- Average document 1 MB
- 100 million users
- Supporting mobile and web applications
Storage Estimations
Let's assume we will have 50 documents per user, 5 versions on average per user. 5 MB * 50 documents * 100kk = 250 000 000 000 MB ~ 25 PB of storage.
Roles Analysis
We will have owners, who are able to invite people. The editors can edit the document, and leave comments, but can't invite anyone. Commenters can not edit anything but can leave comments, and edit the delete their own comments as well. Readers can only see the document and comments.
Communication Protocol
The main challenge of the task is the collaborative edit. The naive solution is to provide the blocking mechanism: while one is editing the document, the others can only observe. This is called a pessimistic lock. We could also detect if the document was edited by another person and show a warning to a user that the changes are going to be rewritten. That is called an optimistic lock. However, those solutions provide a bad user experience, which is not suitable. We need an approach which allows us to truly edit the document in real-time collaboratively. This is a solved problem from the computer science perspective. We need a data structure which can accept the change events and yield the same result even if those events come in a different order. The Operation Transformation algorithm allows doing that. Find an illustration:
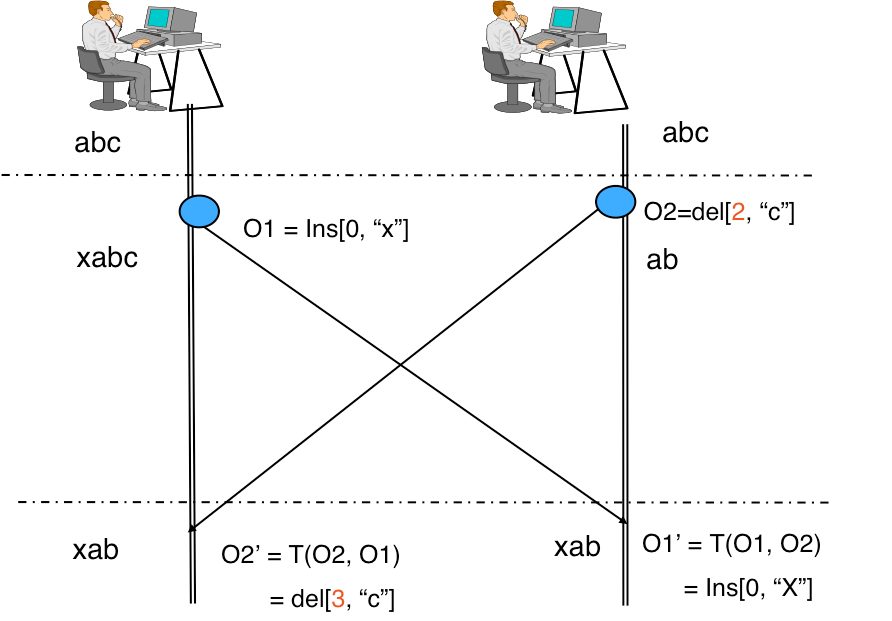
So, we're starting with the line "abc". The person on the left is adding an "x" at the first position. The person on the right is deleting a letter at position 3. If we apply both operations we will get "xab" on both sides.
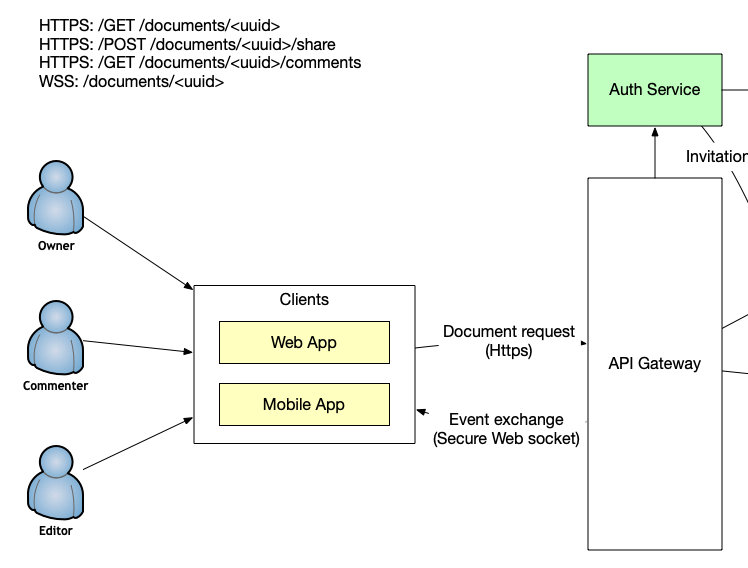
That means we need an event-based protocol to send changes from the client and receive changes from other participants. But surely beforehand we need to request the document itself. So, we will use HTTP operations for accessing the documents and take actions regarding it, like sharing. All the editing operations will go through the secure WebSocket. We can pick JSON-RPC 2.0 protocol for those actions. WebSocket is a bidirectional protocol: when the connection is established the client is sending and receiving the events simultaneously.
Data Storage
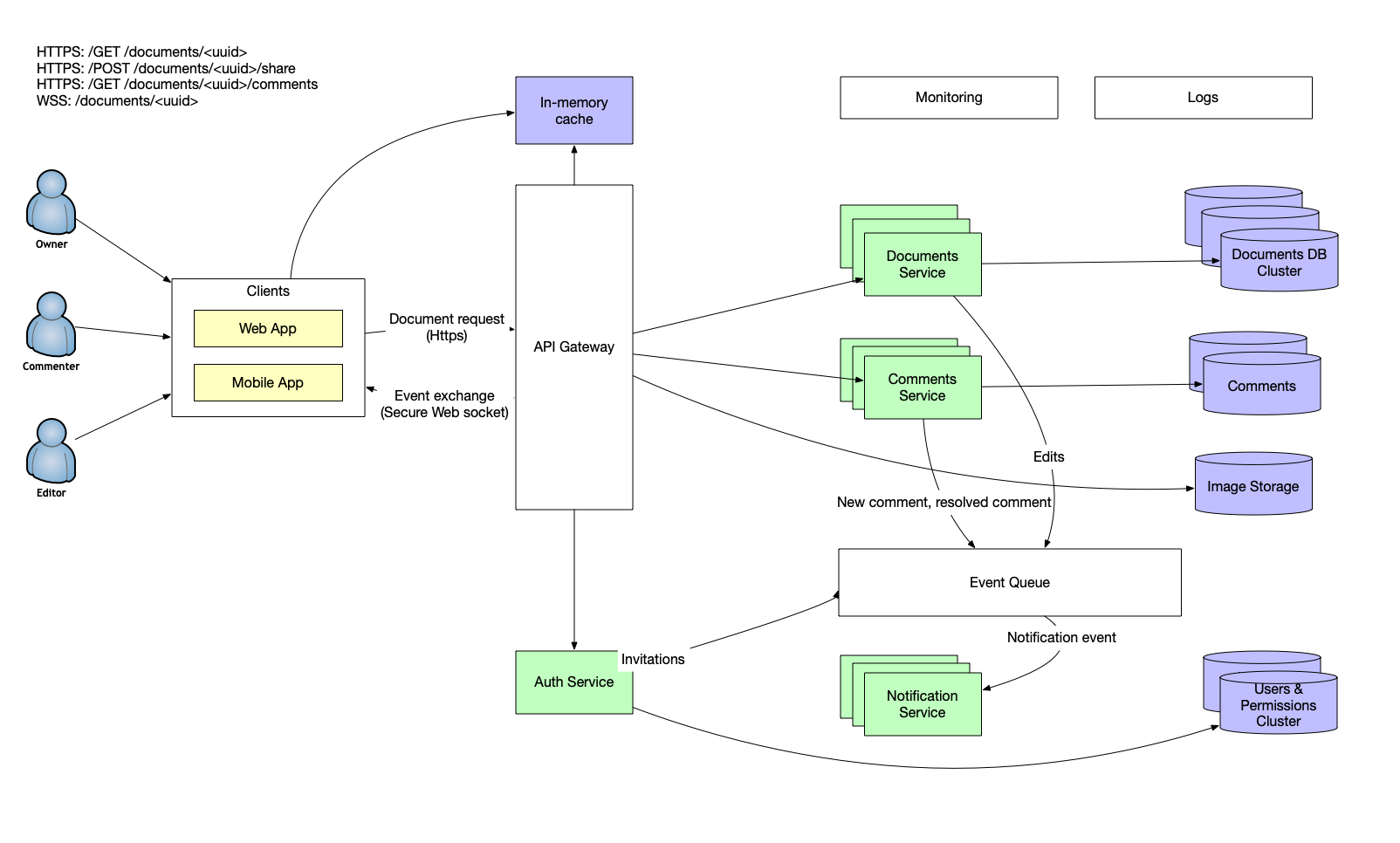
Let's talk about data storage. As we have documents, which don't have a lot of relational data, we can pick some NoSQL storage. We can use key-value or document-based. As we want to know what happens inside the document I would pick the document-based DB. We will identify the document by UUID v4 instead of numbers. We will avoid brute-forcing document numbers with it. To support the styling and images, we can pick Markdown to store the document itself and separate binary storage to upload images to. Once the client application encounters the image link in the document it is responsible to download and show it to the user.
Also, given the amount of data going NoSQL will allow scaling relatively easy as we can shard the documents by the first several bytes of the UUID. We will also require a separate database for users and their permissions. Another DB we will use is the Comments database.
Surely, having the data split across 3 databases is discussible. For the pros, this allows to separate the concerns properly and pick the DB technology independently. It also has the advantage of increased fault tolerance: if something goes wrong with comments let's say, we will just not be able to see and edit the comments, but the overall functionality will work. For the cons, it means harder maintenance and higher expertise required if we pick different technologies.
Logic and notifications
It's time to understand how the changes reach the database. We will employ API Gateway to accept both document requests and editing events. All those requests should be authenticated and authorized. If there is no permission for the particular user to edit the document, such a request should not be routed to the Documents Service. If the user is not allowed to see the document at all, then again we should not serve the document. To invite a new user to the document the Auth Service will generate an invite event and pass it to the event queue. A Notification Service will get the notification and gracefully handle it via sending an email, generating a push or doing something else. We will also use the same approach to notify users about comments being resolved or replied to.
Non-Functional Requirements
Security
We want to make sure that the documents are intact and accessible to the users with the proper rights. We already discussed the permissions and how we are going to use them at the API Gateway level. Although protecting the access logic, those measures are not enough. First of all, we need to make sure all the data at transfer is encrypted to prevent leaking the data. That's why all client communication happens only through HTTPS and WSS: those protocols leverage TLS to encrypt the traffic. We will also need to verify the server identity to avoid MitM attacks. For example, we will use SSL pinning on the mobile device. Ideally, we also want to secure data at rest and encrypt the data storage.
Reliability
We will use master-slave replication for the database shards. The microservices will be stateless and replicated as well. We will monitor their health and load, and spin up new instances if it is required. We will use an event queue for both the edit events and the notifications to make sure they do reach the users and are not lost in the process.
Performance
In order to support the proper document performance, we will shard the databases to balance the load of the nodes. We will also scale the services according to the CPU and Memory consumption metrics. We will include the in-memory cache to improve performance.
Final Scheme
If you liked the article consider supporting the content on Patreon.