

Architecture Weekly Issue #89. Articles, books, and playlists on architecture and related topics. Split by sections, highlighted with complexity: 🤟 means hardcore, 👷♂️ is technically applicable right away, 🍼 - is an introduction to the topic or an overview. Now in telegram as well.
WARNING 🇺🇦
It's already been a year and a half since Russia's crazy, brutal and unjustified war against Ukraine. We condemn this war and want it to stop ASAP. We continue this newsletter so you can advance your skill and help the millions of Ukrainian people in any way possible. If you want to help directly, visit this fund.
Big thanks to Nikita, Anatoly, Oleksandr, Dima, Pavel B, Pavel, Robert, Roman, Iyri, Andrey, Lidia, Vladimir, August, Roman, Egor, Roman, Evgeniy, Nadia, Daria and Dzmitry for supporting the newsletter. They receive early access to the articles, influence the content and participate in the closed group where we discuss the architecture problems. They also see my daily updates on all the things I am working on. Join them at Patreon or Boosty!
Highlights
How Cloudflare mitigated yet another Okta compromise 🍼
Okta got another security incident this year connected with their support system. It allows to upload the files with recorded sessions including authentication tokens. Cloudflare was able to notice the attack even before Okta does and actually notify them. The impressive part is Cloudflare's Zero Trust Architecture allowed them to prevent any impact whatsoever.

#security
Should you use a Lambda Monolith, aka Lambdalith? 👷♂️
When we started our pet-project, I wandered how should I better use lambda functions? Put each route into a separate function or deploy a monolith into Lambda? I tried the former approach, but discovered promptly the hastle of sharing the code - not only the libraries, but domain definitions as well. And now I found the article with proper explanation of pros and cons of both approaches. Grab a great post!
 Rehan van der Merwe
Rehan van der Merwe
#lambda #aws #architecture
Building a reliable notification system at Contentsquare 👷♂️
Notifications, especially email ones, can be difficult. And scaling them is no easy too. Contentsquare published a piece on how the notification system works for them, sending Slack and MS Teams messages alongside emails leveraging Kafka topics. Observability for all the channels is crucial, otherwise your customers will miss important notifications. Problems, Illustrations and explanations inside!
 Joseph-Emmanuel Banzio
Joseph-Emmanuel Banzio
#casestudy
Follow-Up
Why Your Reliability Problems are Really Traffic Problems 🍼
What does it mean exactly to have a reliable system? It means to have redundancy, to failover properly and know when things go south(observability). While the first reason for troubles are code and/or config changes, the second will be traffic. You either get much more traffic than expected, or you lose a part of your compute resources, be it some pods or an entire cloud region. The article features 4 patterns to employ in the time of such events.
 Matthew Girard
Matthew Girard
Encrypted traffic interception target the largest Russian XMPP messaging service
You may rightfully wander if anybody is still using XMPP messages, but apparently somebody does. And moreover, there are people who want to read what those people talk about. Find a super-detailed post on how the MitM attack was discovered. Chain of thought, screenshots from WireShark and many more network details attached!

#network #security
Exploring How the ScyllaDB Data Cache Works 👷♂️
Interesting piece in the ScyllaDB blog(they hosted free P99 conference last Thursday btw) explaining how in-memory cache works for them. The article covers the overall idea, row granularity and other details.
 Tomasz Grabiec
Tomasz Grabiec
#db #cache #performance
Microservice without reason 🍼
Small article on our favourite topic: microservices. Felix Seemann shortly explains why microservices by default is a bad idea on the example of explicit dependencies in the monolith become implicit in microservices and share the list of problems which are signs you're doing something wrong ;)

#microservice
LinkedIn Elevated Its Risk and Compliance Platform 🍼
Risk and Compliance are often linked to manual labor, long processing times and poor stakeholder experience. LinkedIn transitions it's risk operations from various tools and services into a single platform, learning along the way that key to success it good data modelling and design collaboration with the consumer teams.
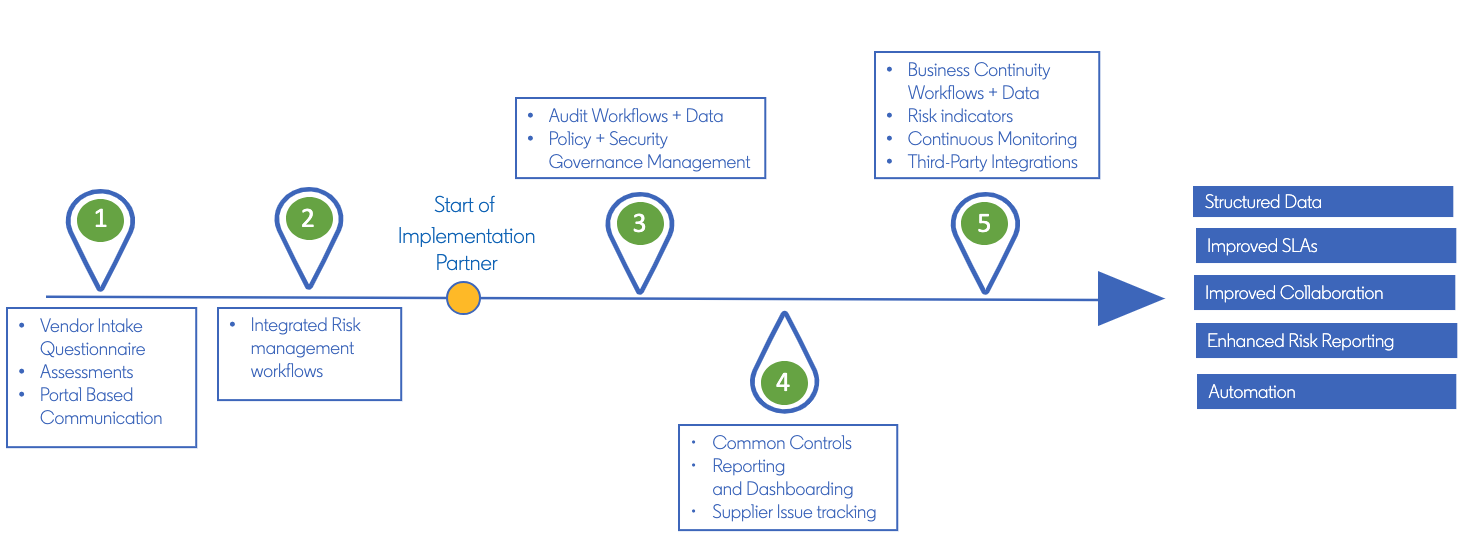
#riskmanagement
The Theory and Practice of Failure Transparency 🤟
Can't let you go without a paper! Researchers from the University of Michigan have published a groundbreaking paper that delves into the concept of "failure transparency" in operating systems. The paper argues for an abstraction layer that makes system and application failures invisible to users and developers, aiming to revolutionize how we perceive and handle software failures with failure transparency, consistent recovery and technical insights.
#paper #failure