

Architecture Weekly Issue #83. Articles, books, and playlists on architecture and related topics. Split by sections, highlighted with complexity: 🤟 means hardcore, 👷♂️ is technically applicable right away, 🍼 - is an introduction to the topic or an overview. Now in telegram as well.
WARNING 🇺🇦
It's already been a year and a half since Russia's crazy, brutal and unjustified war against Ukraine. We condemn this war and want it to stop ASAP. We continue this newsletter so you can advance your skill and help the millions of Ukrainian people in any way possible. If you want to help directly, visit this fund.
Big thanks to Nikita, Anatoly, Oleksandr, Dima, Pavel B, Pavel, Robert, Roman, Iyri, Andrey, Lidia, Vladimir, August, Roman, Egor, Roman, Evgeniy, Nadia, Daria and Dzmitry for supporting the newsletter. They receive early access to the articles, influence the content and participate in the closed group where we discuss the architecture problems. They also see my daily updates on all the things I am working on. Join them at Patreon or Boosty!
Highlights
Distributed Systems with Dominik Tornow 🍼
This week I conducted the interview on Distributed Systems with Dominik Tornow. We discussed their history, biggest current challenges, the importance of mental models and scratched the idea of formal verification, which we would probably discuss some time later. Watch the talk!
#video #distributedsystems
Creating an integrated business and technology strategy 🍼
Commerce department at Bolt is now going through the phase of creation the strategy for the next several years. While we do it in our own way, which I will probably cover in this blog, Martin Fowler's blog featured an article on creating integrated and technology strategy. Sarah Taraporewalla suggests that technology should not follow the business strategy, but both should be developed at the same time. In the article she shows the possible strategic directions and business and technology questions which should answered. Go and get yourself acknowledged!

#strategy
Difficulty of Architectural Decisions – A Survey with Professional Architects 🤟
The paper presents a survey with 43 industry architects, examining 86 real-world architectural decisions. Findings indicate decisions take an average of eight working days, with dependencies between decisions being a major difficulty factor. Notably, 86% of architectural decisions are made by groups. Comparatively, junior architects spend significantly less time on decisions than senior architects.
#architecture #study
Follow-Up
Measuring developer productivity? A response to McKinsey 👷♂️
McKinsey published their methodology of measuring individual developer productivity. Gergely Orosz and Kent Beck wrote a reply together to express the skepsis. It appears, that the suggested methodology focuses on effort and output - like number of pull requests - instead of outcome and impact. TL;DR: if you're up to measure something, measure the team's outcomes and impact, not the individual output - people are not studip, they will game it otherwise.
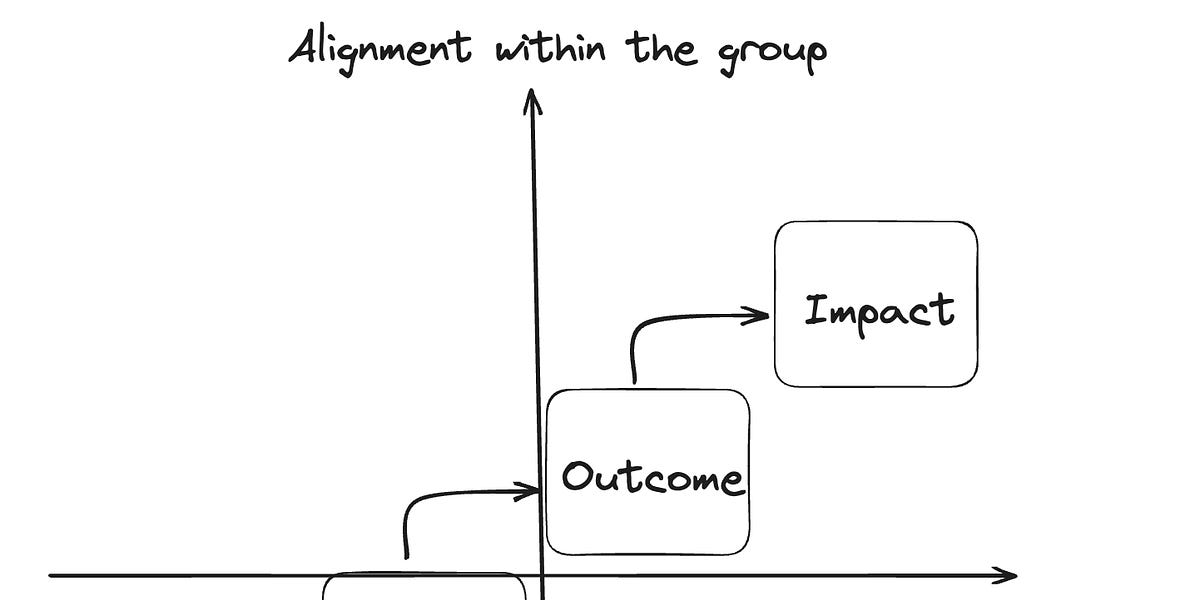
#process
The Great Re-shard: adding Postgres capacity again with zero downtime 👷♂️
Notion scale is pretty significant. Starting with a single PostgreSQL instance in Amazon RDS, they quickly grew to 32 shards. However, at some point even this became too small for their load and they faces a problem of further scaling. After considering several options, Notion engineers decided to proceed to horizontally scale up to 96 instances. Find out how they did it step by step.
As a side note, I am personally triggered at "On top of that, distributing load across more machines meant we’d be able to tune the discrete instances to match their traffic since some shards experience greater load than others". They mention they are using a random workspace id which is used to identify the shard - that was probably a place to optimize first.
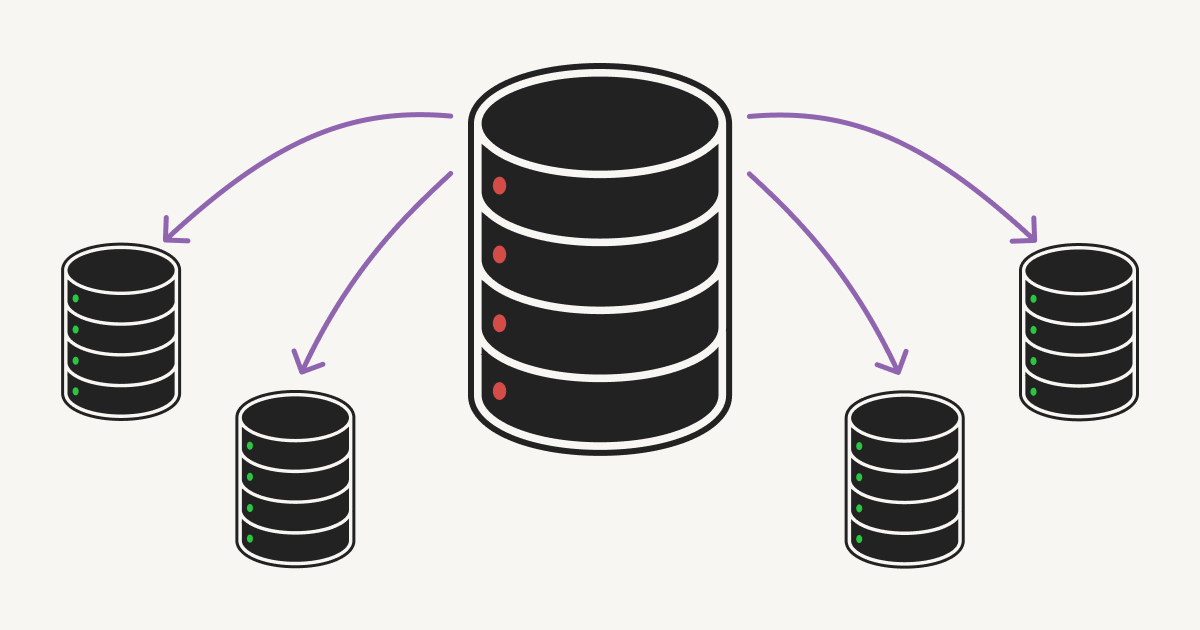
#db
Intro to Serverless Monitoring 🍼
Observability is essential to understanding what is happenning within your system. Traditional tools tailored around a monolith is doing poor job providing insights in the serverless environment. Thus you need to understand what changes around monitoring, logs and tracing in the serverless environment. Please read an article from Helios on the topic.
 Helios
Helios
#observability #serverless
Analyzing Time Series for Pinterest Observability 👷♂️
Pinterest's Observability heavily relies on time series, powering numerous alerts and dashboards. This article delves into the evolution of time series solutions at Pinterest, transitioning from tools like Ganglia, Graphite, and OpenTSDB to their current solution, Goku. Recognizing the limitations of previous tools, Pinterest developed a time series script, TScript, to perform operations on the returned time series data. TScript offers features like multi-line input, object-oriented operations, and built-in alerting, making it more readable and efficient. The article also touches upon challenges faced during TScript's implementation, its success in transforming data, and potential future optimizations.
Zero Configuration Service Mesh with On-Demand Cluster Discovery at Netflix 👷♂️
Netflix discusses its historical journey with Inter-Process Communication (IPC) and the evolution from using tools like Eureka and Ribbon to adopting a service mesh approach. The article delves into the challenges faced with traditional IPC methods and how the service mesh, particularly with Envoy, offers a centralized solution. The piece highlights the collaboration with Kinvolk and the Envoy community to develop the On-Demand Cluster Discovery (ODCDS) feature. This feature allows proxies to fetch cluster information at runtime, streamlining the migration to a service mesh without requiring extensive configuration.
#microservices #servicemesh #availability #reliability
Why Engineering Manager should review pull requests 🍼
Engineering Manager is a position which causes a lot of questions regarding it's responsiblities. One of the questions is 'Should EM review PRs?'. Please find an article by Emily Dresner, where she explains the difference between an Engineering Manager and a Tech Lead, and why EM should probably not do the reviews.

#process