

Architecture Weekly Issue #81. Articles, books, and playlists on architecture and related topics. Split by sections, highlighted with complexity: 🤟 means hardcore, 👷♂️ is technically applicable right away, 🍼 - is an introduction to the topic or an overview. Now in telegram as well.
WARNING 🇺🇦
It's already been a year since Russia's crazy, brutal and unjustified war against Ukraine. We condemn this war and want it to stop ASAP. We continue this newsletter so you can advance your skill and help the millions of Ukrainian people in any way possible. If you want to help directly, visit this fund.
Big thanks to Nikita, Anatoly, Oleksandr, Dima, Pavel B, Pavel, Robert, Roman, Iyri, Andrey, Lidia, Vladimir, August, Roman, Egor, Roman, Evgeniy, Nadia, Daria and Dzmitry for supporting the newsletter. They receive early access to the articles, influence the content and participate in the closed group where we discuss the architecture problems. They also see my daily updates on all the things I am working on. Join them at Patreon or Boosty!
Highlights
Product competitor with the 100 times less codebase 🍼
Mastodon - a social network competitor to Twitter - claims to be 100 times smaller in the size of the code base and written only in 9 man-month. The secret sauce to their success is the engine called Rama which is, as I understood, half the way to store data and half how to process it. Find out the insides of this platform in the blog post by Red Planet Labs.
Serverless Patterns 👷♂️
Have you ever heard about the SALAD stack? Turns out this is exactly what I am using in a pet project :) It resolves to S3 - API Gateway - LAmbda - DynamoDB. I found out this in the blog post which goes through 8 microservices patterns some of which are pretty fresh and I haven't heard or thought about never before. Find the list inside.

#serverless #microservices
Cadence 1.0: Scalable Workflow Orchestration Platform by Uber
When I worked for a bank, we used Camunda to implement the multistep workflow reliably and fast. In a microservice world, you somehow need to write to multiple databases at once, so you either employ something like Sagas or go with a workflow manager like Camunda or... Cadence. The latter had it's major release recently. Uber Engineering Blog posted a long article on the requirements to the distributed systems, their own scale and how Cadence allow them to perform well. Check it out!
#distributedsystem
Follow-Up
Prompt injection with control characters in ChatGPT 👷♂️
As ChatGPT gained popularity, security specialists also gained interest in it. The folks from Dropbox started evaluating it for building some customer-facing products, and no wonder they were concerned about security. They did interesting research on prompt injection, hallucinations and other stuff. If you consider building something on top of a Chatbot - this is definitely a must-read.
#ai
AWS vs Azure vs GCP IAM services comparison 🍼
IAM is an inseparable part of the modern cloud, as you have to govern the access to the resource for different user groups. The Big 3 of the cloud providers naturally have those services implemented, but it might be useful to understand the similarities and differences between them. For example, if you migrate from one cloud provider to another. Here you can find a comparison of IAM services, including pricing, limitations and capabilities in the blog of Pluralsight.
#cloud #iam
Analyzing Volatile Memory on a Google Kubernetes Engine Node 🤟
Speaking of GCP, Spotify shared an article on how they analyze memory anomalies in their Kubernetes pods. Running several hundreds of thousands of pods across 5 regions, Spotify gained some expertise in the field. Find their article on the topic here!
#gcp #gke
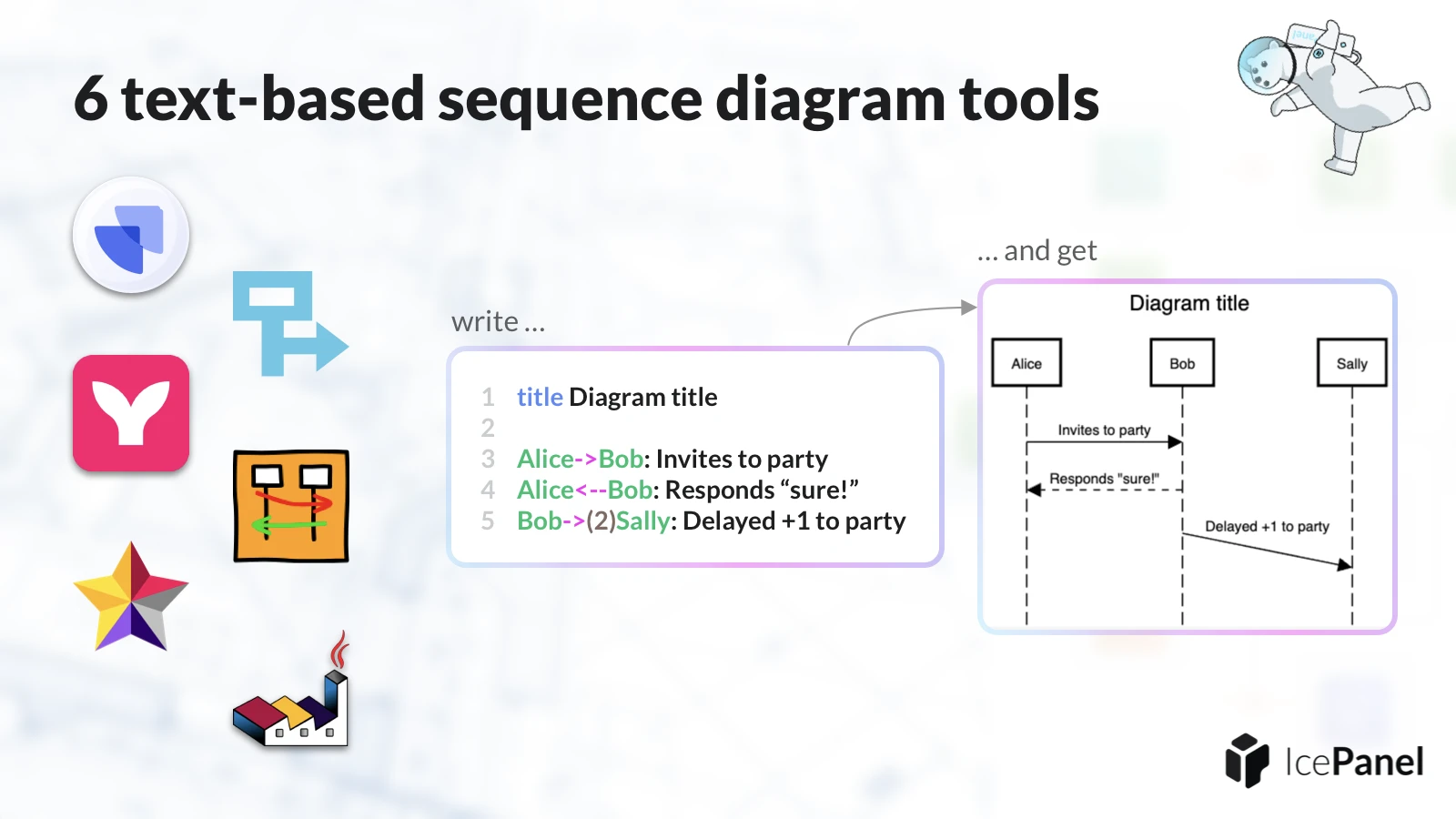
Top 6 tools for text-based UML sequence diagrams 🍼
Sequence diagrams are a crucial element of architecture documentation, facilitating the understanding of data flows and use cases. As a proponent of PlantUML, I am advocating of creating the sequence diagrams with UML as well. But PlantUML is not the only tool to do that! Find out the post with 6 different tools which will help with the task.
#diagrams #documents
Geospatial Data Analysis in ClickHouse
Geospatial data is applied in multiple fields like logistics, transportation, finances, healthcare and many more. For Software Architects it is important to understand how the data can be stored and encoded, and which storages handle the task well. My former colleague, Igor Gorbenko wrote a post with a description of 3 geospatial hash algorithms and provided a comparison of their performance using ClickHouse. Find the numbers, graphics and explanations inside!
#database #clickhouse #data #geo
Inside InfluxDB 3.0: Exploring DB's Scalable and Decoupled Architecture
InfluxDB 3.0 is a database tailored for time series data, offering scalability and optimization. The system is structured around four main components that manage data ingestion, querying, compaction, and garbage collection. All data is categorized into two primary storage types: the Catalog, which holds metadata, and Object Storage, which contains the actual data. When data enters the system, it's processed and validated by 'Ingesters'. Queries are directed by the 'Query Router' and executed by a 'Querier'. To enhance performance, InfluxDB 3.0 compacts smaller files into larger ones and employs garbage collection for efficient data retention. Communication within the system is facilitated through the Catalog and Object Storage, with data being stored in versatile Parquet files, making it compatible with both local and various cloud storage solutions. For a comprehensive understanding, it's recommended to explore the original article.

#db #timeseries