

Architecture Weekly Issue #110. Articles, books, and playlists on architecture and related topics. Split by sections, highlighted with complexity: 🤟 means hardcore, 👷♂️ is technically applicable right away, 🍼 - is an introduction to the topic or an overview. Now in telegram and Substack as well.
If you're interested in the technologies, development approaches and overall business of our little startup in the compliance field subscribe on Patreon and Boosty, as I shared an article recently on how we added a second product to our architecture last week.
Highlights
How Figma’s databases team lived to tell the scale 👷♂️
Until 2020s Figma was living on a single PostgreSQL machine(relatively huge though). At that point they realized they need to scale and started considering options to either switch to NoSQL, or scale PostgreSQL. They decided for the latter and after 9 month they managed to shard their highly loaded first table. Find the journey how it happened with little changes to developer experience in this amazing article by Figma.
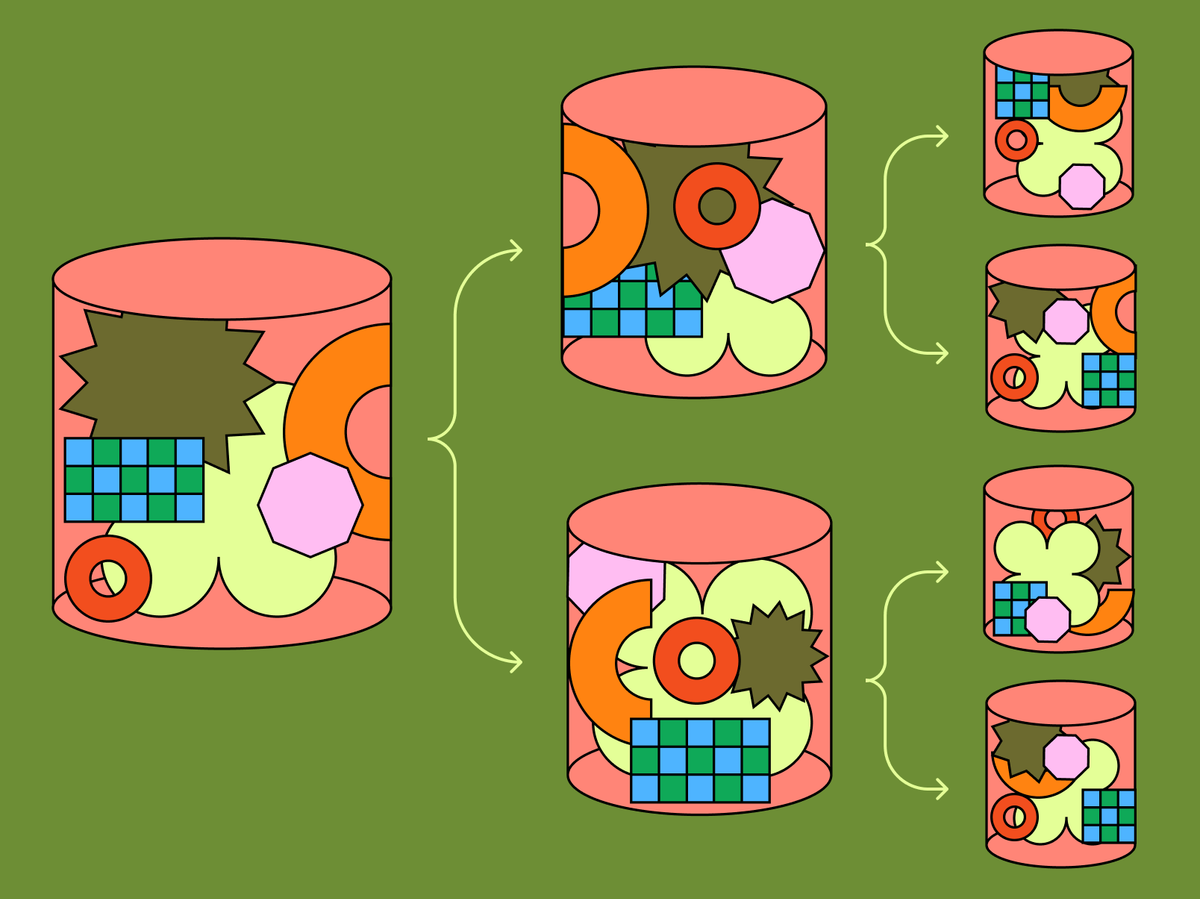
#casestudy #db #scalability
The Copenhagen Book 👷♂️
Mentees ask about what to read to understand the authentication and authorization problematic and tactics to address them. So here you are: The Copenhagen book explains what are the sessions, tokens, multifactor authentication and encryption around them. Great stuff!
#security
Casual Consistency in MongoDB 🤟
Serializability, Linearizability... Those are strong consistency guarantees, but what about a more relaxed one - casual consistency? It denotes the guarantee that the client will see the events linked by the causal order in that order, however non-causal events can have different order. This paper describes how the testing of Casual Consistency was done against MongoDB and what is the actual support level there.
#paper #db
Follow-Up
Understandability as the primary software design goal 🍼
We have security, performance, scalablity among the NFRs, but this article argues that the most important one is understability - otherwise you won't achieve others. It also contains the tactics to achieve understability, like isolating complexity and surprisingly - changing the code according to the code review comments, instead of explaining in the reply.
#requirements #documentation
Lambda Environment Variables' Impact on Coldstart 👷♂️
Surprisingly, if you have env variables in lambda, your cold start will be approx. 25 ms longer, than in the case without env variables. Find this piece explaining the experiment, the result and whether you should be bothered by this fact.
 David Behroozi Founder
David Behroozi Founder
#lambda #aws #performance
Another cloud article, this time on S3 🍼
If you start thinking about file systems and for example Unix Filesystem API, you will discover that you can seek to a particular location in the file to read or write a piece of data. But partial write is not supported in S3 meaning the models are incompatible and running let's say SQLite on S3 is extremely impractical. Possible, but impractical. Nice piece on how to think about s3 and some notes about it as well.
 Cal Paterson
Cal Paterson
#s3
Distributed Tracing Guide: Quick Overview 👷♂️
Observability solutions gets enough attention, but how tracing works in a nutshell on the side of your application? Here distributed tracing is explained in less than 10 minutes, including spans, traces and relations between them.
#observability
Personalized, interest-based feed curation 👷♂️
Modern personalization in social networks works on machine learning, but for a young product it can be long and difficult to bring ML for this problem. How you can bring personalized feed without ML? Find a post by Hashnode exactly on that.
 Florian Fuchs
Florian Fuchs
#casestudy